
[혼공머신러닝] 7 - 1 인공신경망
인공신경망
1. 용어 정리
인공신경망 : 생물학적 뉴런에서 영감을 받아 만든 머신러닝 알고리즘
텐서플로 : 구글이 만든 딥러닝 라이브러리로 CPU와 GPU를 사용해 인공 신경망 모델을 효율적으로 훈련하며 모델 구축과 서비스에 필요한 다양한 도구를 제공한다.
밀집층 : 가장 간단한 인공 신경망의 층
원-핫 인코딩 : 정숫값을 배열에서 해당 정수 위치의 원소만 1이고 나머지 모두 0으로 변환한다.
2. 인공신경망
2 - 1. 패션 mnist
텐서플로의 케라스(Keras) 패키지를 임포트하고 패션 MNIST 데이터를 다운로드합니다.
from tensorflow import keras
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
훈련 데이터에 60,000개의 이미지로 이루어져 있고 28X28 사이즈의 크기인것을 확인해 볼 수 있습니다.
print(train_input.shape, train_target.shape)
(60000, 28, 28) (60000,)
맷플롭립 라이브러리를 통해 과일을 출력했던 것처럼 훈련 데이터 10개를 그림으로 출력을 해봅니다.
import matplotlib.pyplot as plt
fig, axs = plt.subplots(1, 10, figsize=(10,10))
for i in range(10):
axs[i].imshow(train_input[i], cmap='gray_r')
axs[i].axis('off')
plt.show()

파이썬의 리스트 내포를 사용해 위에서 뽑은 10개의 샘플의 타깃값을 리스트로 만든 후 출력을 해봅니다.타깃은 0~9까지로 이루어져있습니다.
print([train_target[i] for i in range(10)])
[9, 0, 0, 3, 0, 2, 7, 2, 5, 5]
출력한 값들은 다음과 같이 나타낼 수 있습니다.

0~9까지 레이블마다 6,000개의 샘플이 들어있는 것을 확인해 볼 수 있습니다.
import numpy as np
print(np.unique(train_target, return_counts=True))
(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8), array([6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000]))
2 - 2. 로지스틱 회귀로 패션 아이템 분류하기
훈련샘플이 60,000개나 되기 때문에 전체 데이터를 한꺼번에 사용하는 것보다 샘플을 하나씩 꺼내서 훈련시키는 방법이 더 효율적입니다. -> 확률적 경사 하강법
SGDClassifier를 사용할 때 표준화 전처리된 데이터를 사용합니다. 확률적 경사 하강법은 여러 특성 중 기울기가 가장 가파른 방향을 따라 이동합니다. 특성마다 값의 범위가 많이 다르면 올바르게 손실 함수의 경사를 내려올 수 없습니다.
SGDClassifier은 2차원 입력을 다루지 못하므로 샘플을 1차원 배열로 만들어 줍니다.
train_scaled = train_input / 255.0
train_scaled = train_scaled.reshape(-1, 28*28)
변환된 train_scaled를 확인해보면 784개의 픽셀로 이루어진 60000개의 샘플로 되었음을 볼 수 있습니다.
print(train_scaled.shape)
(60000, 784)
cross_validate함수를 사용해 데이터에서 교차 검증으로 성능을 확인해 봅니다.
from sklearn.model_selection import cross_validate
from sklearn.linear_model import SGDClassifier
sc = SGDClassifier(loss='log', max_iter=5, random_state=42)
scores = cross_validate(sc, train_scaled, train_target, n_jobs=-1)
print(np.mean(scores['test_score']))
0.8195666666666668
2 - 3. 인공 신경망으로 모델 만들기
import tensorflow as tf
from tensorflow import keras
인공신경망에서는 교차 검증을 사용하지 않고 검증 세트를 별도로 덜어내어 사용합니다. 이렇게 하는 이유는
- 딥러닝 분야의 데이터셋은 충분히 크기 때문에 검증 점수가 안정적입니다.
- 교차 검증을 수행하기에는 훈련 시간이 오래 걸리기 때문입니다.
훈련 세트에서 20%를 검증 세트로 덜어 낸 다음 훈련 세트와 검증 세트의 크기를 알아봅니다.
from sklearn.model_selection import train_test_split
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)
60,000개 중 12,000개각 검증 세트로 분리된 것을 확인해 볼 수 있습니다.
print(train_scaled.shape, train_target.shape)
(48000, 784) (48000,)
print(val_scaled.shape, val_target.shape)
(12000, 784) (12000,)
인공 신경망 그림의 오른쪽에 놓인 층을 만들어 보면 10개의 패션 아이템을 분류하기 위해 10개의 뉴런으로 구성됩니다.
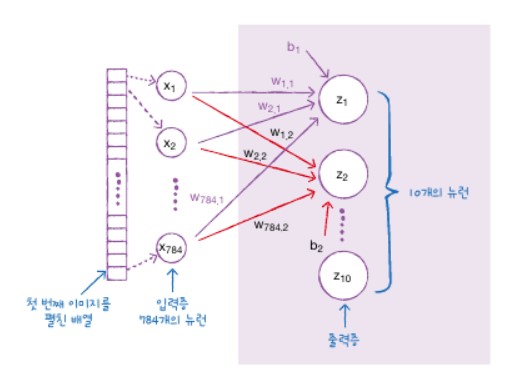
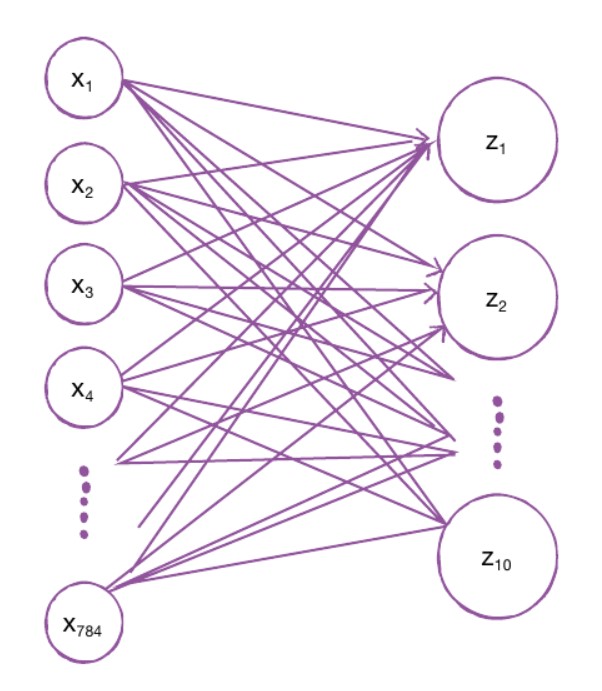
다음 그림에서 왼쪽에 있는 784개의 픽셀과 오른쪽에 있는 10개의뉴런이 모두 연결되어 있습니다. 총 784 *10 = 7,840개의 연결된 선들이 있습니다. 이러한 이유로 밀집층이라고 불립니다.
케라스의 Dense 클래스를 사용해 밀집층을 만들어 봅니다.
dense = keras.layers.Dense(10,activation='softmax', input_shape=(784,))
# 10은 뉴런 개수 ,activation='softmax'는 뉴런의 출력에 적용할 함수, input_shape=(784,)는 입력의 크기입니다.
케라스의 Sequential클래스를 사용해봅니다.
model = keras.Sequential(dense)
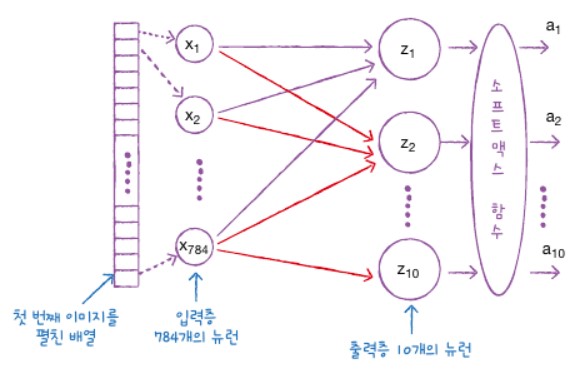
2 - 4. 인공신경망으로 패션 아이템 분류하기
케라스에서 손실 함수를 밑에와 같이 부릅니다. 이진 분류: loss = ‘binary_crossentropy’ 다중 분류: loss = ‘categorical_crossentropy’
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
print(train_target[:10])
[7 3 5 8 6 9 3 3 9 9]
사이킷런의 로지스틱 모델과 동일하게 5번 반복해 줍니다. 정확도가 85%를 넘은 것을 확인해 볼 수 있습니다.
model.fit(train_scaled, train_target, epochs=5)
Epoch 1/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.6113 - accuracy: 0.7953
Epoch 2/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.4791 - accuracy: 0.8401
Epoch 3/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.4580 - accuracy: 0.8475
Epoch 4/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.4450 - accuracy: 0.8516
Epoch 5/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.4375 - accuracy: 0.8558
<keras.callbacks.History at 0x7fd2d2195950>
evaluate() 메서드도 fit() 메서드와 비슷한 출력을 보여줍니다.
model.evaluate(val_scaled, val_target)
375/375 [==============================] - 1s 2ms/step - loss: 0.4627 - accuracy: 0.8428
[0.4627155661582947, 0.8427500128746033]
공부한 전체 코드는 깃허브에 올렸습니다.
댓글남기기