
[혼공머신러닝] 3 - 2 선형 회귀
선형 회귀
1. 용어 정리
선형 회귀 : 특성과 타깃 사이의 관계를 가장 잘 나타내는 선형 방정식을 찾습니다. 특성이 하나면 직성 방정식이 됩니다.
모델 파라미터 : 선형 회귀가 찾은 가중치처럼 머신러닝 모델이 학습한 파라미터를 말합니다.
다항 회귀 : 다항식을 사용하여 특성과 타깃 사이의 관계를 나타냅니다. 이 함수는 비선형일 수 있지만 여전히 선형 회귀로 표현할 수 있습니다.
2. 문제 풀이
2 - 1. k-최근접 이웃 회귀의 문제점
지금까지 k-최근접 이웃 회귀 모델을 통해 만들었습니다. 그런데 모델을 학습 시킨 후, 50cm인 농어의 무게를 예측해보니 약 1,033g 정도로 예측했습니다. 실제 무게인 1.5kg과는 상당한 차이가 나는걸 확인해 볼 수 있습니다.
import numpy as np
perch_length = np.array([8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0, 21.0,
21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5, 22.5, 22.7,
23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5, 27.3, 27.5, 27.5,
27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0, 36.5, 36.0, 37.0, 37.0,
39.0, 39.0, 39.0, 40.0, 40.0, 40.0, 40.0, 42.0, 43.0, 43.0, 43.5,
44.0])
perch_weight = np.array([5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0, 110.0,
115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0, 130.0,
150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0, 197.0,
218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0, 514.0,
556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0, 820.0,
850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0, 1000.0,
1000.0])
from sklearn.model_selection import train_test_split
# 훈련 세트와 테스트 세트로 나눕니다
train_input, test_input, train_target, test_target = train_test_split(
perch_length, perch_weight, random_state=42)
# 훈련 세트와 테스트 세트를 2차원 배열로 바꿉니다
train_input = train_input.reshape(-1, 1)
test_input = test_input.reshape(-1, 1)
from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor(n_neighbors=3)
# k-최근접 이웃 회귀 모델을 훈련합니다
knr.fit(train_input, train_target)
print(knr.predict([[50]]))
[1033.33333333]
2 - 2. 선형 회귀
선형 회귀는 널리 사용되는 대표적인 회귀 알고리즘입니다. 특성이 하나인 경우 어떤 직선을 학습하는 알고리즘으로 k-최근접 이웃 회귀 알고리즘의 단점을 보완할 수 있습니다.
from sklearn.linear_model import LinearRegression # 선형 회귀
lr = LinearRegression()
# 선형 회귀 모델 훈련
lr.fit(train_input, train_target)
# 50cm 농어에 대한 예측
print(lr.predict([[50]]))
[1241.83860323]
선형 회귀 모델로 훈련한 결과 길이가 50인 농어에 대해 k-최근접 회귀보다 조금 더 정확한 값인 1241.83860323kg이 나왔습니다.
직선 $y=ax+b$로 나타낼 수 있습니다. $x$는 농어의 길이, $y$는 농어의 무게로 바꾸면 다음과 같습니다.
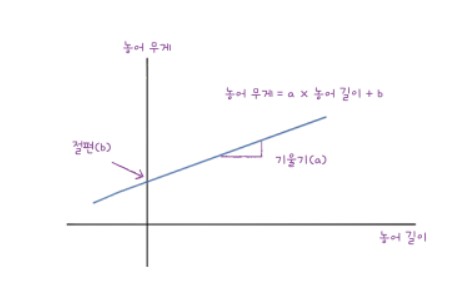
기울기인 $a$와 $y$절편인 $b$를 다음과 같이 확인해줍니다.
print(lr.coef_, lr.intercept_)
전체적으로 과소적합이 되었다는걸 볼 수 있습니다.
print(lr.score(train_input, train_target))
print(lr.score(test_input, test_target))
0.939846333997604
0.8247503123313558
[39.01714496] -709.0186449535477
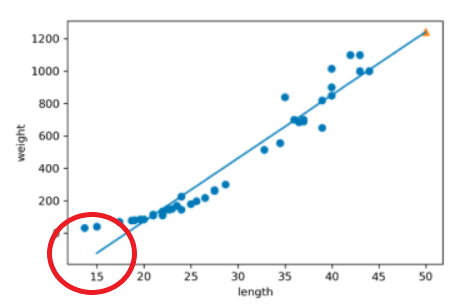
선형 회귀로 만든 직선이 왼쪽 아래로 뻗어 있습니다. 이렇게 되면 농어의 무게가 0g 밑으로 내려가 문제가 생깁니다.
2 - 3. 다항 회귀
다항 회귀는 앞서 보여준 선형 회귀의 문제점을 보완해줍니다. 최적의 직선보다 최적의 곡선으로 나타내줍니다.
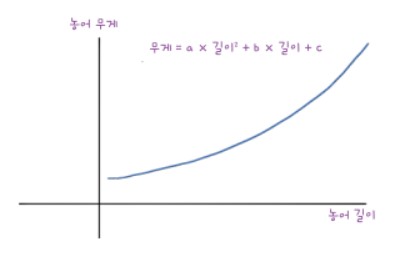
이처럼 2차 방정식의 그래프를 그리려면 길이를 제곱한 항이 훈련 세트에 추가되어야 합니다.
lr = LinearRegression()
lr.fit(train_poly, train_target)
print(lr.predict([[50**2, 50]]))
[1573.98423528]
선형 회귀로 훈련한 모델보다 더 높은 값을 예측했습니다. 훈련한 계수와 절편을 출력을 해보면 밑에와 같이 나옵니다.
print(lr.coef_, lr.intercept_)
[ 1.01433211 -21.55792498] 116.0502107827827
print(lr.score(train_poly, train_target))
print(lr.score(test_poly, test_target))
0.9706807451768623
0.9775935108325122
훈련 세트와 테스트 세트에 대한 점수가 크게 높아졌지만 테스트 점수가 더 높은걸 볼 수 있습니다. 그러므로 과소적합이 남아있다고 해석할 수 있습니다.
공부한 전체 코드는 깃허브에 올렸습니다. https://github.com/mgskko/Data_science_Study-hongongmachine/blob/main/%ED%98%BC%EA%B3%B5%EB%A8%B8%EC%8B%A0_3%EA%B0%95_2.ipynb
댓글남기기