
[혼공머신러닝] 4 - 1 로지스틱 회귀
로지스틱 회귀
1. 용어 정리
로지스틱 회귀 : 선형 방정식을 사용한 분류 알고리즘으로 선형 회귀와 달리 시그모이드함수나 소프트맥스 함수를 사용해 클래스 확률을 출력할 수 있습니다.
다중 분류 : 타깃 클래스가 2개 이상인 불류 문제로 소프트맥스 함수를 사용합니다.
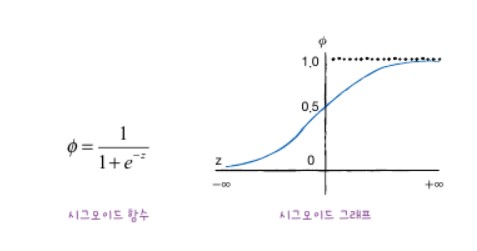
시그모이드 함수 : 선형 방정식의 출력을 0과 1 사이의 값으로 압축하여 이진 분류를 위해 사용합니다.
소프트맥스 함수 : 다중 분류에서 여러 선형 방정식의 출력 결과를 정규화하여 합이 1이 되도록 합니다.
2. 데이터 구하기
이번에 해야할 문제는 혼공머신이 구성품이 랜덤으로 담겨있는 생선의 확률을 구하는 것이다. 생선은 총 7개로 길이, 높이, 두께 등 사용할 수 있다. 먼저 K-최근접를 사용하여 클래스 확률을 계산해본다.
unique함수를 사용하여 Species열에서 고유값한 값을 추출해 봅니다.
import pandas as pd
fish = pd.read_csv('https://bit.ly/fish_csv')
print(pd.unique(fish['Species']))
['Bream' 'Roach' 'Whitefish' 'Parkki' 'Perch' 'Pike' 'Smelt']
Species 열을 제외한 나머지 5개 열은 입력 데이터로 사용합니다. 데이터프레임에서 원하는 열을 리스트로 나열하기 위해 넘파이 배열로 만듭니다..
fish_input = fish[['Weight', 'Length', 'Diagonal', 'Height', 'Width']].to_numpy()
[[242. 25.4 30. 11.52 4.02 ]
[290. 26.3 31.2 12.48 4.3056]
[340. 26.5 31.1 12.3778 4.6961]
[363. 29. 33.5 12.73 4.4555]
[430. 29. 34. 12.444 5.134 ]]
print(fish_input[:5])
[[242. 25.4 30. 11.52 4.02 ]
[290. 26.3 31.2 12.48 4.3056]
[340. 26.5 31.1 12.3778 4.6961]
[363. 29. 33.5 12.73 4.4555]
[430. 29. 34. 12.444 5.134 ]]
훈련 세트와 테스트 세트로 나눕니다.
fish_target = fish['Species'].to_numpy()
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
fish_input, fish_target, random_state=42)
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
2 - 1. k-최근접 이웃 분류기의 확률 예측
훈련 세트와 테스트 세트로 나눠준 후 KNeighborsClassifier 클래스를 통해 최근접 이웃 개수를 3개로 지정합니다. 훈련 세트와 테스트 세트의 타깃 데이터에도 7개의 생선 종류가 들어가 있습니다. 이렇듯 타깃 데이터에 2개 이상의 클래스가 포함된 문제를 다중 분류라고 합니다.
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier(n_neighbors=3)
kn.fit(train_scaled, train_target)
print(kn.score(train_scaled, train_target))
print(kn.score(test_scaled, test_target))
0.8907563025210085
0.85
테스트 세트에 있는 5번째 까지의 타깃값을 예측해보니 이름 그대로 나옵니다.
print(kn.predict(test_scaled[:5]))
['Perch' 'Smelt' 'Pike' 'Perch' 'Perch']
사이킷런의 분류 모델은 predict_proba() 메서드로 클래스별 확률값을 반환합니다.
import numpy as np
proba = kn.predict_proba(test_scaled[:5])
print(np.round(proba, decimals=4)) # ← 소수점 네 번째 자리까지 표기합니다. 다섯 번째 자리에서 반올림합니다.
[[0. 0. 1. 0. 0. 0. 0. ]
[0. 0. 0. 0. 0. 1. 0. ]
[0. 0. 0. 1. 0. 0. 0. ]
[0. 0. 0.6667 0. 0.3333 0. 0. ]
[0. 0. 0.6667 0. 0.3333 0. 0. ]]
네 번째 샘플의 최근접 이웃 클래스를 확인 해보니 ‘Roach’가 1개, ‘Perch’가 2개로 나옵니다. 3개의 최근접 이웃을 사용했기 때문에 확률은 0/3, 1/3, 2/3, 3/3 이렇게 4가지로만 나옵니다. 이러한 문제를 해결하기 위해서 로지스틱 회귀를 사용합니다.
distances, indexes = kn.kneighbors(test_scaled[3:4])
print(train_target[indexes])
[['Roach' 'Perch' 'Perch']]
3. 로지스틱 회귀
로지스틱 회귀는 이름은 회귀이지만 분류 모델입니다.
$z=a × (Weight) + b × (Length) + c × (Diagonal) + d × (Height) + e × (Width) + f$
로지스틱 회귀에 사용할 함수는 시그모이드 함수입니다. 시그모이드 함수는 S자형 곡선 또는 시그모이드 곡선을 갖는 수학 함수이다 여기서 $a,b,c,d,e$는 가중치 혹은 계수입니다. 시그모이드 함수(로지스틱 함수)는 확률이 되려면 0 ~ 1 사이의 값이 되어야 합니다. $z$가 아주 큰 음수일 때 0이 되고, $z$가 아주 큰 양수일 경우에는 1이 됩니다.
넘파이를 사용해 그래프를 간단히 그려 보겠습니다.
import numpy as np
import matplotlib.pyplot as plt
z = np.arange(-5, 5, 0.1)
phi = 1 / (1 + np.exp(-z))
plt.plot(z, phi)
plt.xlabel('z')
plt.ylabel('phi')
plt.show()
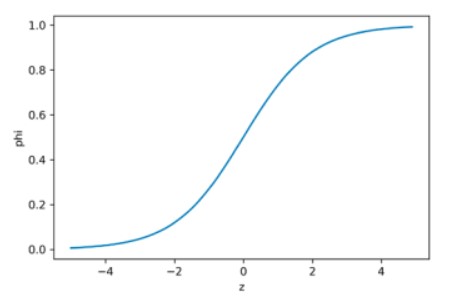
여기서 정확히 0.5일경우에는 라이브러리마다 다릅니다. 사이킷런에서는 0.5는 음성 클래스로 판단합니다.
3 - 1. 로지스틱 회귀로 이진 분류 수행하기
불리언 인덱싱을 사용하여 도미와 빙어의 행만 골라냅니다. 도미와 빙어에 대한 비교 결과를 비트 OR연산자를 사용해 도미와 빙어에 대한 행만 골라냅니다.
bream_smelt_indexes = (train_target == 'Bream') | (train_target == 'Smelt')
train_bream_smelt = train_scaled[bream_smelt_indexes]
target_bream_smelt = train_target[bream_smelt_indexes]
train_bream_smelt에서 처음 5개 샘플의 예측 확률을 출력해 봅니다.
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_bream_smelt, target_bream_smelt)
print(lr.predict_proba(train_bream_smelt[:5]))
print(lr.classes_)
[[0.99759855 0.00240145]
[0.02735183 0.97264817]
[0.99486072 0.00513928]
[0.98584202 0.01415798]
[0.99767269 0.00232731]]
['Bream' 'Smelt']
첫 번째 열이 음성 클래스(0)에 대한 확률이고 두 번째 열이 양성 클래스(1)에 대한 확률입니다. classes_를 통해 빙어(Smelt)가 양성 클래스임을 알 수 있습니다.
로지스틱 회귀가 학습한 계수를 확인해 봅니다.
print(lr.coef_, lr.intercept_)
[[-0.4037798 -0.57620209 -0.66280298 -1.01290277 -0.73168947]] [-2.16155132]
로지스틱 회귀 모델이 학습한 방정식은 밑과 같습니다.
$z=-0.404 × (Weight) -0.576 × (Length) -0.663 × (Diagonal) − 1.013 × (Height) - 0.732 × (Width) -2.161$
로지스틱 회귀 또한 선형 회귀와 비슷한 것을 확인해 볼 수 있습니다. 사이파이 라이브러리에는 시그모이드 함수(expit())가 있습니다. 이를 사용하여 배열의 값을 확률로 바꿔줍니다.
scipy.special import expit
print(expit(decisions))
[0.00240145 0.97264817 0.00513928 0.01415798 0.00232731]
3 - 2. 로지스틱 회귀로 다중 분류 수행하기
다중 분류는 시그모이드 함수를 대신해 소포트맥스 함수를 사용하여 7개의 z값을 확률로 반환해 줍니다.
from scipy.special import softmax
proba = softmax(decision, axis=1)
print(np.round(proba, decimals=3))
[[0. 0.014 0.841 0. 0.136 0.007 0.003]
[0. 0.003 0.044 0. 0.007 0.946 0. ]
[0. 0. 0.034 0.935 0.015 0.016 0. ]
[0.011 0.034 0.306 0.007 0.567 0. 0.076]
[0. 0. 0.904 0.002 0.089 0.002 0.001]]
proba 배열과 비교해 보면 결과가 일치한 것을 확인해 볼 수 있습니다.
공부한 전체 코드는 깃허브에 올렸습니다. https://github.com/mgskko/Data_science_Study-hongongmachine/blob/main/%ED%98%BC%EA%B3%B5%EB%A8%B8%EC%8B%A0_4%EA%B0%95_1.ipynb
댓글남기기