
[혼공머신러닝] 5 - 2 교차 검증과 그리드 서치
교차 검증과 그리드 서치
1. 용어 정리
검증 세트 : 하이퍼파라미터 튜닝을 위해 모델을 평가할 때, 테스트 세트를 사용하지 않기 위해 훈련세트에서 떼어 낸 데이터 세트
교차 검증 : 훈련 세트를 여러 폴드로 나눈 다음 한 폴드가 검증 세트의 역할을 하고 나머지 폴드에서는 모델을 훈련합니다. 교차 검증은 이런 식으로 모든 폴드에 대해 검증 점수를 얻어 평균하는 방법이다.
그리드 서치 : 하이퍼파라미터 탐색을 자동화해 주는 도구
랜덤 서치 : 연속된 매개변수 값을 탐색할 때 유용합니다. 탐색한 값을 직접 나열하는 것이 아닌 탐색 값을 샘플링할 수 있는 확률 분포 객체를 전달합니다.
2. 검증 세트
2 - 1. 검증 세트를 사용하는 이유
지금까지 문제를 간단히 하려고 테스트 세트를 사용했습니다. 하지만 테스트 세트로 일반화 성능을 올바르게 예측하려면 한가지의 테스트 세트를 사용하지 말아야 합니다. 또 결정 트리는 테스트해 볼 매개변수가 많습니다. 테스트 세트를 사용하지 않으면 모델이 과대적합인지 과소적합인지 판단하기 어렵습니다. 테스트 세트를 사용하지 않고 측정하는 간단한 방법은 훈련 세트를 또 나누는 방법이 있습니다. 이를 검증 세트라고 합니다. 훈련 세트 중 20%를 떼어 내어 검증 세트로 만들어 줍니다.
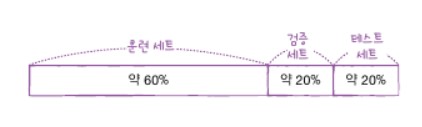
기존에 해왔듯이 데이터를 불러와 타깃과 분리 후, 훈련 세트와 테스트 세트를 저장합니다. 여기서 이제 훈련세트를 통해 검증세트를 20% 또 떼어냅니다.
import pandas as pd
wine = pd.read_csv('https://bit.ly/wine_csv_data')
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)
sub_input, val_input, sub_target, val_target = train_test_split(train_input, train_target, test_size=0.2, random_state=42)
print(sub_input.shape, val_input.shape)
(4157, 3) (1040, 3)
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(sub_input, sub_target)
print(dt.score(sub_input, sub_target))
print(dt.score(val_input, val_target))
0.9971133028626413
0.864423076923077
2 - 2. 교차 검증
많은 데이터를 훈련에 사용할수록 좋은 모델이 만들어집니다. 검증 세트를 너무 조금 떼어 놓으면 성능이 불안정해지기 때문에 교차 검증을 사용해 안정적인 검증 점수를 얻고 훈련에 더 많은 데이터를 사용합니다. 교차 검증은 검증 세트를 떼어 내어 평가하는 과정을 반복합니다. 보통 5-폴드 교차 검증과 10-폴드 교차 검증을 사용합니다. 사이킷런 안에 있는 cross_validate() 교차 검증 함수를 사용합니다.
from sklearn.model_selection import cross_validate
scores = cross_validate(dt, train_input, train_target)
print(scores)
{'fit_time': array([0.02356291, 0.01329517, 0.013026 , 0.01336861, 0.01058364]), 'score_time': array([0.00849509, 0.00127387, 0.0011611 , 0.000983 , 0.0011301 ]), 'test_score': array([0.86923077, 0.84615385, 0.87680462, 0.84889317, 0.83541867])}
교차 검증을 수행하면 입력한 모델에서 얻을 수 있는 최상의 검증 점수를 가늠해 볼 수 있습니다.
import numpy as np
print(np.mean(scores['test_score']))
0.855300214703487
훈련 세트를 섞은 후 10-폴드 교차 검증을 수행하려면 아래와 같습니다.
splitter = StratifiedKFold(n_splits=10, shuffle=True, random_state=42)
scores=cross_validate(dt, train_input, train_target, cv=splitter)
print(np.mean(scores['test_score']))
0.8574181117533719
3. 하이퍼파라미터 튜닝
모델이 학습할 수 없어 사용자가 지정해야만 하는 파라미터를 하이퍼파라미터라고 합니다. 사이킷런과 같은 머신러닝 라이브러리를 사용할 때 이런 하이퍼파라미터는 모두 클래스나 메서드의 매개변수로 표현합니다. 하이퍼파라미터를 튜닝하는 작업은 라이브러리가 제공하는 기본값을 그대로 사용해 모델을 훈련합니다. 그다음 검증 세트의 점수나 교차 검정을 통해 매개변수를 조금씩 바꿔주면 훈련하고 교차 검증을 수행합니다. 매개변수가 많아지면 문제는 더 복잡해집니다. 파이썬의 for문으로 구현할 수 있지만 사이킷런에서는 그리드 서치를 사용합니다. GridSearchCV 클래스를 임포트하고 탐색할 매개변수와 탐색할 값의 리스트를 딕셔너리로 만들어줍니다.
기본 매개변수를 사용한 결정 트리 모델에서 min_impurity_decrease 매개변수의 최적값을 찾는 예를 보면 0.0001부터 0.0005까지 0.0001씩 증가하는 5개의 값 중에서 최적의 파라미터를 찾아볼 것입니다.
from sklearn.model_selection import GridSearchCV
params = {'min_impurity_decrease': [0.0001, 0.0002, 0.0003, 0.0004, 0.0005]}
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params,n_jobs=-1)
gs.fit(train_input, train_target)
GridSearchCV(estimator=DecisionTreeClassifier(random_state=42), n_jobs=-1,
param_grid={'min_impurity_decrease': [0.0001, 0.0002, 0.0003,
0.0004, 0.0005]})
dt = gs.best_estimator_
print(dt.score(train_input,train_target))
0.9615162593804117
최적은 매개변수는 bestparams에 있어 0.0001이 가장 좋은 값으로 선택이 되었습니다.
print(gs.best_params_)
{'min_impurity_decrease': 0.0001}
print(gs.cv_results_['mean_test_score'])
[0.86819297 0.86453617 0.86492226 0.86780891 0.86761605]
best_index = np.argmax(gs.cv_results_['mean_test_score'])
print(gs.cv_results_['params'][best_index])
{'min_impurity_decrease': 0.0001}
params = {'min_impurity_decrease' : np.arange(0.0001,0.001,0.01),
'max_depth': range(5,20,1),
'min_samples_split' : range(2,100,10)}
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1)
gs.fit(train_input, train_target)
GridSearchCV(estimator=DecisionTreeClassifier(random_state=42), n_jobs=-1,
param_grid={'max_depth': range(5, 20),
'min_impurity_decrease': array([0.0001]),
'min_samples_split': range(2, 100, 10)})
print(gs.best_params_)
{'max_depth': 19, 'min_impurity_decrease': 0.0001, 'min_samples_split': 2}
print(np.max(gs.cv_results_['mean_test_score']))
0.86780780336122
최상의 매개변수 조합을 확인 해 본 결과 ‘max_depth’은 19, ‘min_impurity_decrease’은 0.0001, ‘min_samples_split’은 2가 나왔습니다.
4. 랜덤 서치
매개변수의 값이 수치일 때 값의 범위나 간격을 미리 정하기 어려운 경우가 있습니다. 너무 많은 매개변수 조건이 있어 그리드 서치 수행 시간이 오래 걸리는 경우 또한 있습니다. 이러한 경우는 랜덤 서치를 사용합니다.
먼저 싸이파이에서 2개의 확률 분포 클래스를 임포트 해줍니다.
from scipy.stats import uniform, randint
1000개를 샘플링해서 각 숫자의 개수를 세어 봅니다.
np.unique(rgen.rvs(1000), return_counts=True)
(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]),
array([ 98, 112, 102, 86, 96, 104, 95, 94, 111, 102]))
ugen = uniform(0, 1)
ugen.rvs(10)
array([0.98405681, 0.85868906, 0.83250683, 0.68183389, 0.80594453,
0.12303783, 0.71651681, 0.20185559, 0.90494683, 0.18959732])
params = {'min_impurity_decrease': uniform(0.0001, 0.001),
'max_depth': randint(20, 50),
'min_samples_split': randint(2, 25),
'min_samples_leaf': randint(1, 25)
}
from sklearn.model_selection import RandomizedSearchCV
gs = RandomizedSearchCV(DecisionTreeClassifier(random_state=42), params, n_iter=100, n_jobs=-1, random_state=42)
gs.fit(train_input, train_target)
RandomizedSearchCV(estimator=DecisionTreeClassifier(random_state=42),
n_iter=100, n_jobs=-1,
param_distributions={'max_depth': <scipy.stats._distn_infrastructure.rv_frozen object at 0x7fe2979c5c90>,
'min_impurity_decrease': <scipy.stats._distn_infrastructure.rv_frozen object at 0x7fe297971c90>,
'min_samples_leaf': <scipy.stats._distn_infrastructure.rv_frozen object at 0x7fe297986950>,
'min_samples_split': <scipy.stats._distn_infrastructure.rv_frozen object at 0x7fe2979c5410>},
random_state=42)
최고의 교차 검증 점수도 확인해 봅니다.
print(gs.best_params_)
{'max_depth': 39, 'min_impurity_decrease': 0.00034102546602601173, 'min_samples_leaf': 7, 'min_samples_split': 13}
print(np.max(gs.cv_results_['mean_test_score']))
0.8695428296438884
dt = gs.best_estimator_
print(dt.score(test_input, test_target))
0.86
다양한 매개변수를 테스트해 얻은 결과가 수동으로 매개변수를 바꾸는 것보다 좋은 결과가 나온 것을 확인해 볼 수 있습니다.
공부한 전체 코드는 깃허브에 올렸습니다. https://github.com/mgskko/Data_science_Study-hongongmachine/blob/main/%ED%98%BC%EA%B3%B5%EB%A8%B8%EC%8B%A0_5%EA%B0%95_2.ipynb
댓글남기기