
[혼공머신러닝] 6 - 2 k - 평균
k - 평균
1. 용어 정리
k -평균 : 처음에 랜덤하게 클러스터 중심을 정하고 클러스터를 만듭니다. 그다음 클러스터의 중심을 이동하고 다시 클러스터를 만드는 식으로 반복해서 최적의 클러스터를 구성하는 알고리즘입니다.
클러스터 중심 : k- 평균 알고리즘이 만든 클러스터에 속한 샘플의 특성 평균값입니다.
엘보우 방법 : 최적의 클러스터 개수를 정하는 방법 중 하나로 이너셔는 클러스터 중심과 샘플 사이 거리의 제곱 합입니다. 클러스터 개수에 따라 이너셔 감소가 꺾이는 지점이 적절한 클러스터 개수 k가 됩니다.
2. k - 평균 알고리즘
k - 평균 알고리즘
- 작동방식
- 무작위로 k개의 클러스터 중심을 정한다.
- 각 샘플에서 가장 가까운 클러스터 중심을 찾아 해당 클러스터의 샘플로 지정한다.
- 클러스터에 속한 샘플의 평균값으로 클러스터 중심을 변경한다.
- 클러스터 중심에 변화가 없을 때까지 2번으로 돌아가 반복한다.
2 - 1. kmeans 클래스
데이터를 다운로드한 후에 npy파일을 읽습니다. k-평균 모델을 훈련하기 위해 3차원 배열을 2차원 배열로 변경해줍니다. (너비, 높이 -> 너비 X 높이)
!wget https://bit.ly/fruits_300_data -O fruits_300.npy
import numpy as np
fruits = np.load('fruits_300.npy')
fruits_2d = fruits.reshape(-1, 100*100)
from sklearn.cluster import KMeans
km = KMeans(n_clusters=3, random_state=42)
km.fit(fruits_2d)
KMeans(n_clusters=3, random_state=42)
각 클러스터가 어떤 이미지를 나타냈는지 그림으로 출력하기 위해 유틸리티 함수인 draw_fruits()를 만들어 줍니다. 각 레이블마다 이미지를 확인해봅니다.
import matplotlib.pyplot as plt
def draw_fruits(arr, ratio=1):
n = len(arr) #n은 샘플 개수입니다.
# 한줄에 10개씩 이미지를 그립니다. 샘플 개수를 10으로 나누어 전체 행 개수를 계산합니다.
rows = int(np.ceil(n/10))
# 행이 1개이면 열의 개수는 샘플 개수입니다. 그렇지 않으면 10개입니다.
cols = n if rows < 2 else 10
fig, axs = plt.subplots(rows,cols, figsize=(cols*ratio, rows*ratio), squeeze=False)
for i in range(rows):
for j in range(cols):
if i *10 + j < n: #n개까지만 그립니다
axs[i,j].imshow(arr[i*10+j],cmap='gray_r')
axs[i,j].axis('off')
plt.show()
draw_fruits(fruits[km.labels_==0])

draw_fruits(fruits[km.labels_==1])

draw_fruits(fruits[km.labels_==2])

구현은 하기는 했지만 아쉽게도 파인애플 사이에 사과와 바나나가 섞여있는것을 확인해 볼 수 있습니다. k-평균 알고리즘을 사용해 완벽하게 분류하지는 못해지만 그래도 얼추 비슷한 샘플끼리 모인것을 확인해 볼 수 있습니다.
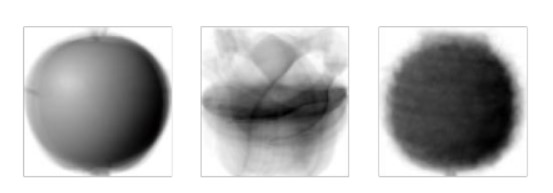
2 - 2. 클러스터 중심
이전 절에서 사과,바나나, 파인애플의 픽셀 평균값과 비슷한것을 확인해 볼 수 있습니다.
draw_fruits(km.cluster_centers_.reshape(-1,100,100),ratio=3)
transform() 메서드를 사용하여 (1,10000)크기의 배열을 전달해줍니다.
print(km.transform(fruits_2d[100:101]))
[[3393.8136117 8837.37750892 5267.70439881]]
print(km.predict(fruits_2d[100:101]))
[0]
draw_fruits(fruits[100:101])

print(km.n_iter_)
4
2 - 3. k 찾기
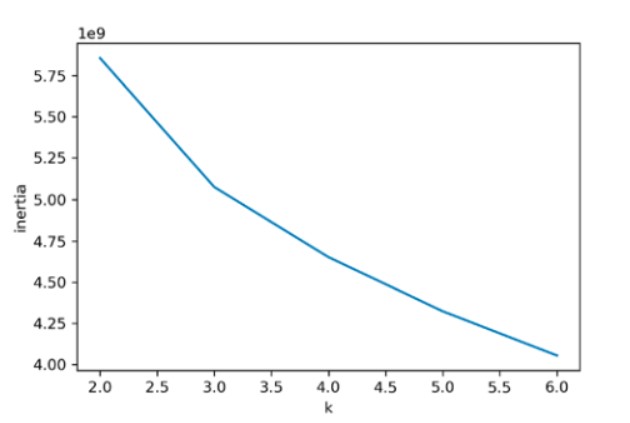
적절한 클러스터 개수를 찾기 위해 대표적인 방법 중 하나인 엘보우 방법을 사용합니다. 엘보우 방법은 클러스터 개수를 늘려가면서 이너셔의 변화를 관찰하여 최적의 클러스터 개수를 찾는 방법입니다. 클러스터 개수를 증가시키면서 이너셔를 그래프로 그리면 감소하는 속도가 꺾이는 지점이 있습니다. 이 지점부터는 클러스터 개수를 늘려도 클러스터에 잘 밀집된 정도가 크게 개선되지 않습니다. transform()을 통해 클러스터 중심과 샘플 사이의 거리를 잴 수 있는데, 이 거리의 제곱의 합을 이너셔라고 부릅니다. 이너셔는 클러스터에 속한 샘플이 얼마나 가깝게 모여 있는지를 나타내는 값입니다. 클러스터 개수를 증가시키면서 이너셔를 그래프로 그리면 꺾이는 지점이 있는데 이 지점을 적절한 클러스터 개수라고 할 수 있습니다. 밑의 그래프는 k가 3에서 기울기 변화가 있습니다.
inertia = []
for k in range(2,7):
km = KMeans(n_clusters = k, random_state=42)
km.fit(fruits_2d)
inertia.append(km.inertia_)
plt.plot(range(2,7), inertia)
plt.xlabel('k')
plt.ylabel('inertia')
plt.show()
공부한 전체 코드는 깃허브에 올렸습니다. https://github.com/mgskko/Data_science_Study-hongongmachine/blob/main/%ED%98%BC%EA%B3%B5%EB%A8%B8%EC%8B%A0_6%EA%B0%95_2.ipynb
댓글남기기