
[혼공머신러닝] 7 - 2 심층신경망
심층신경망
1. 용어 정리
심층 신경망 : 2개 이상의 층을 포함한 신경망으로 종종 다층 인공 신경망, 심층 신경망, 딥러닝을 같은 의미로 사용
렐루 함수 : 이미지 분류 모델의 은닉층에 많이 사용하는 활성화 함수로 시그모이드 함수는 층이 많을수록 활성화 함수의 양쪽 끝에서 변화가 작기 때문에 학습이 어려워진다.
옵티마이저 : 신경망의 가중치와 절편을 학습하기 위한 알고리즘 또는 방법
2. 심층신경망
2 - 1. 2개의 층
케라스 API를 사용해 패션 MNIST를 불러옵니다.
from tensorflow import keras
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()ㅜ
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
32768/29515 [=================================] - 0s 0us/step
40960/29515 [=========================================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz
26427392/26421880 [==============================] - 0s 0us/step
26435584/26421880 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz
16384/5148 [===============================================================================================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz
4423680/4422102 [==============================] - 0s 0us/step
4431872/4422102 [==============================] - 0s 0us/step
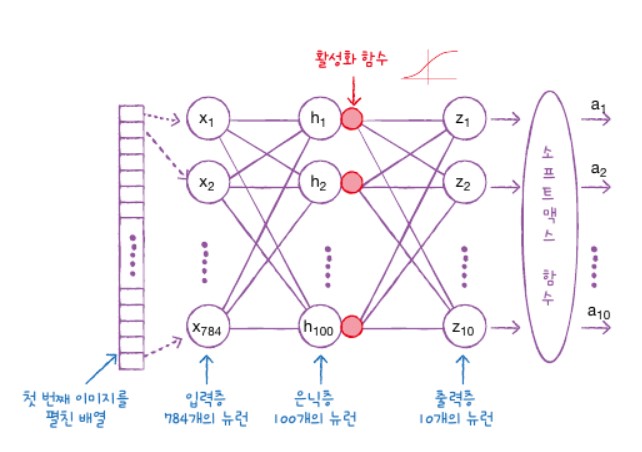
인공 신경망 모델에 층을 2개 추가해보면 다음과 같습니다.
7 -1장에서 만든 신경망 모델에서 입력층과 출력층 사이에 밀집층이 추가가 되었습니다. 이렇게 입력층과 출력층 사이에 있는 모든 층을 은닉층이라 부릅니다. 은닉층에 주황색 원으로 활성화 함수가 표시가 되어 있는데 이 활성화 함수는 신경막 층의 선형 방정식의 계산 값에 적용되는 함수입니다.
소프트맥스 함수도 이 활성화 함수입니다.
출력층에 적용하는 함수는 다음과 같이 있습니다.
- 이진분류일 경우 -> 시그모이드 함수
- 다중분류일 경우 -> 소프트맥스 함수
from sklearn.model_selection import train_test_split
train_scaled = train_input / 255.0
train_scaled = train_scaled.reshape(-1, 28*28)
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
4장에서 배운 시그모이드 활성화 함수를 사용한 은닉층과 소프트맥스 함수를 사용한 출력층을 케라스의 Dense 클래스로 만들어 줍니다. dense1이 은닉층이고 100개의 뉴런을 가진 밀집층입니다. 은닉층은 적어도 출력층의 뉴런보다는 많게 만들어야 됩니다. 왜냐면 클래스 10개에 대한 확률을 예측해야 되는데 이전 은닉층의 뉴런이 10개보다 적다면 부족한 정보를 전달해주기 때문입니다. dense2는 출력층입니다.
dense1 = keras.layers.Dense(100,activation='sigmoid', input_shape=(784,))
dense2 = keras.layers.Dense(10,activation='softmax')
2 - 2. 심층 신경망 만들기
model = keras.Sequential([dense1,dense2])
summary() 메서드를 호출해 정보를 확인해 봅니다. 맨 첫줄은 모델의 이름입니다. 그다음 모델에 들어 있는 층이 순서대로 나옵니다. 출력되는 값은 각각 100개 / 10개의 출력이 나온다. None이 나온 것은 fit 메서드에 훈련 데이터를 주입하면 이 데이터를 한 번에 모두 사용하지 않고 나누어 여러번에 걸쳐 미니배치 경사 하강법 단계를 수행합니다.
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_2 (Dense) (None, 100) 78500
dense_3 (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________
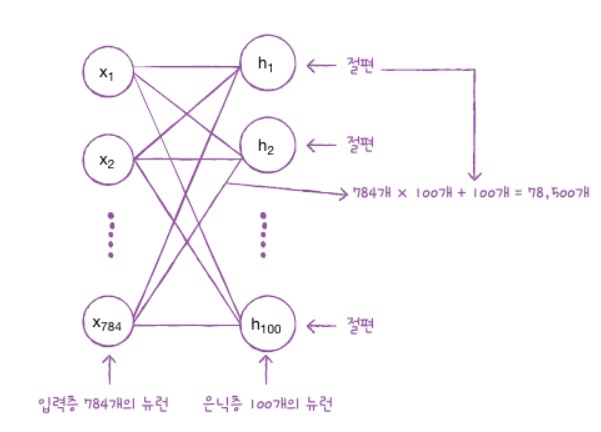
마지막은 모델 파라미터 개수가 출력됩니다. Dense층으로 입력 픽셀 784개와 100개의 모든 조합에 가중치가 있습니다.
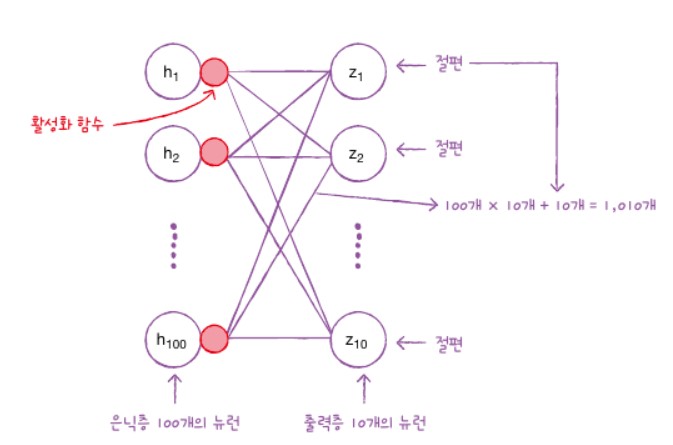
출력층의 파라미터 개수는 은닉층에는 100개의 뉴런이 있고 출력층에는 10개의 뉴런이 있어 총 1010개의 모델 파라미터가 있습니다.
2 - 3. 층을 추가하는 다른 방법
model = keras.Sequential([
keras.layers.Dense(100, activation='sigmoid', input_shape=(784,), name='hidden'),
keras.layers.Dense(10, activation='softmax', name='output')
], name='패션 MNIST 모델')
위와 같이 자업을 하면 추가되는 층을 한눈에 쉽게 알아볼 수 있는 장점이 있습니다.
model.summary()
Model: "패션 MNIST 모델"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
hidden (Dense) (None, 100) 78500
output (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________
add()메서드를 통해 층을 추가해줍니다.
model = keras.Sequential()
model.add(keras.layers.Dense(100, activation='sigmoid', input_shape=(784,)))
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_4 (Dense) (None, 100) 78500
dense_5 (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________
5번의 에포크 동안 훈련을 해줍니다. API의 장점으로 필요시 여러 개의 층을 추가할 수 있습니다.
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
Epoch 1/5
1500/1500 [==============================] - 5s 3ms/step - loss: 0.5630 - accuracy: 0.8072
Epoch 2/5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.4077 - accuracy: 0.8540
Epoch 3/5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.3737 - accuracy: 0.8646
Epoch 4/5
1500/1500 [==============================] - 5s 3ms/step - loss: 0.3499 - accuracy: 0.8730
Epoch 5/5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.3339 - accuracy: 0.8784
<keras.callbacks.History at 0x7ffa973ae450>
2 - 4. 롈루 함수
시그모이드 함수는 양 사이드로 갈수록 그래프가 누워져 있기 때문에 올바른 출력을 만드는데 신속하게 대응하지 못합니다. 특히 층이 많은 심층 신경망일수록 더 어렵습니다. 이를 개선하기 위한 함수가 렐루 함수입니다. 렐루함수는 심층 신경망에서 유용하게 쓰입니다. 렐루 함수는 max(0, z)라고 할 수 있습니다. z가 0보다 크면 z를 출력하고 z가 0보다 작으면 0을 출력합니다.
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
dense_6 (Dense) (None, 100) 78500
dense_7 (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________
reshape() 메서드를 적용하지 않고 모델을 훈련시켜 줍니다.
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
Epoch 1/5
1500/1500 [==============================] - 5s 3ms/step - loss: 0.5315 - accuracy: 0.8140
Epoch 2/5
1500/1500 [==============================] - 6s 4ms/step - loss: 0.3951 - accuracy: 0.8583
Epoch 3/5
1500/1500 [==============================] - 5s 4ms/step - loss: 0.3561 - accuracy: 0.8712
Epoch 4/5
1500/1500 [==============================] - 5s 3ms/step - loss: 0.3340 - accuracy: 0.8797
Epoch 5/5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.3176 - accuracy: 0.8865
<keras.callbacks.History at 0x7ffa97358ed0>
2 - 5. 옵티마이저
케라스는 다양한 종류의 경사하강법을 제공해줍니다. 가장 기본적인 옵티마이저는 확률적 경사 하강법인 SGD입니다. 매개변수를 ‘sgd’로 지정해줍니다.
model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy', metrics='accuracy')
sgd = keras.optimizers.SGD()
model.compile(optimizer=sgd, loss='sparse_categorical_crossentropy', metrics='accuracy')
sgd = keras.optimizers.SGD(learning_rate=0.1)
SGD외에도 다양한 옵티마이저들이 있습니다.
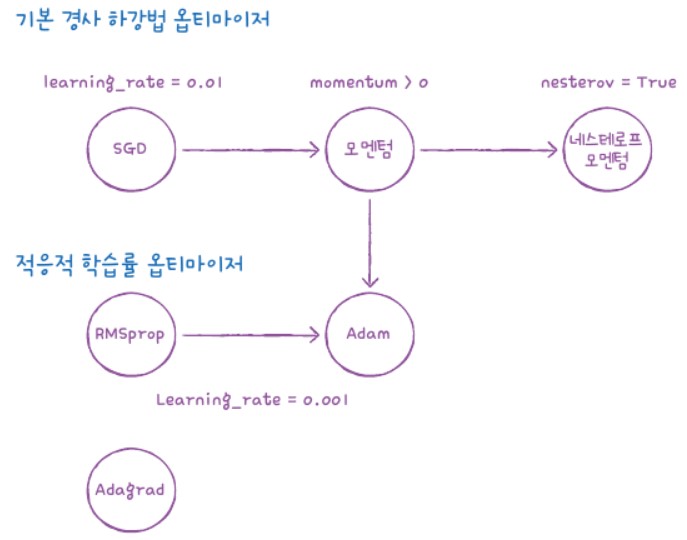
SGD클래스의 nesterov 매개변수를 기본값 False에서 True로 바꾸면 네스테로프 모멘텀 최적화를 사용합니다. 네스테로프 모멘텀 최적화가 기본 확률적 경사하강법보다 더 나은 성능을 제공해줍니다.
sgd = keras.optimizers.SGD(momentum=0.9, nesterov=True)
- Adagrad
adagrade = keras.optimizers.Adagrad()
model.compile(optimizer=adagrade, loss='sparse_categorical_crossentropy', metrics='accuracy')
-RMSprop
rmsprop = keras.optimizers.RMSprop()
model.compile(optimizer=rmsprop, loss='sparse_categorical_crossentropy', metrics='accuracy')
-Adam
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28,28)))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
compile() 메서드의 optimizer를 ‘adam’으로 설정하고 5번의 에포크 동안 훈련해줍니다.
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
Epoch 1/5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.5183 - accuracy: 0.8197
Epoch 2/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3977 - accuracy: 0.8572
Epoch 3/5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.3570 - accuracy: 0.8720
Epoch 4/5
1500/1500 [==============================] - 5s 3ms/step - loss: 0.3288 - accuracy: 0.8804
Epoch 5/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3095 - accuracy: 0.8866
<keras.callbacks.History at 0x7ffa97293fd0>
model.evaluate(val_scaled, val_target)
375/375 [==============================] - 1s 2ms/step - loss: 0.3461 - accuracy: 0.8765
[0.3461076319217682, 0.8765000104904175]
공부한 전체 코드는 깃허브에 올렸습니다.
댓글남기기