
K-means 알고리즘
1. K-means 알고리즘의 개념
k-means 알고리즘은 비지도학습 중에서 간단한 알고리즘 중 하나로 주어진 값들 사이의 거리를 이용하는 분석법이다.데이터을 이용해 Euclidean 거리가 최소가 되도록 K개의 묶음으로 군집(Clustering)하여 분류하는 데이터 마이닝 기법이다.
2. K-means 알고리즘의 특징
- 거리기반 알고리즘이므로 Euclidean 거리가 최소화하는 작업을 반복한다.
- 반복 작업을 통해 초기의 오류를 회복한다.
- 간단한 알고리즘으로, 대규모 적용 가능하다.
3. K-means 알고리즘의 수행절차
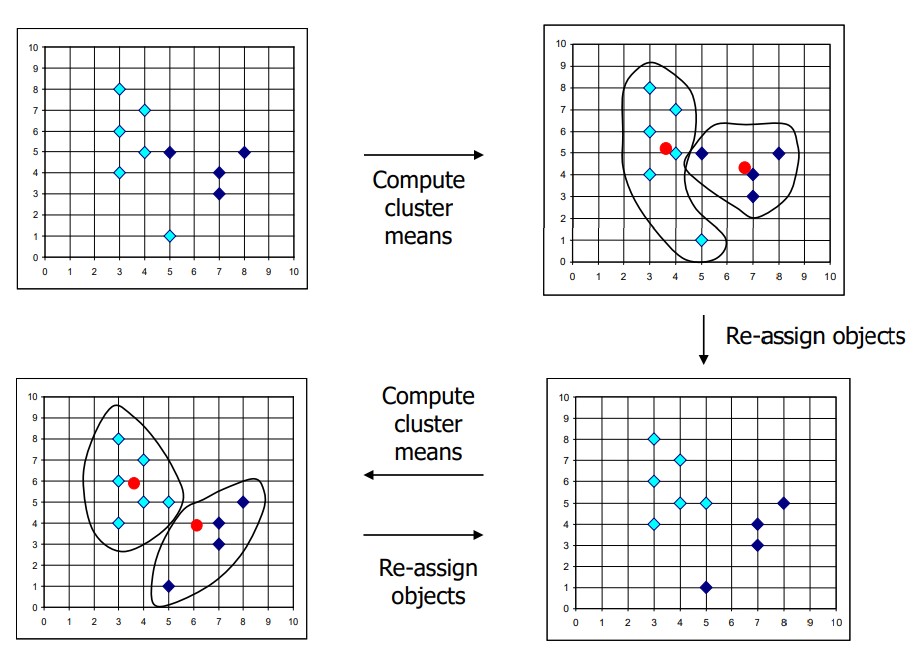
- 클러스터 수 k 정의
- 각 측정값을 가까운 클러스터에 할당
- 새로운 클러스터 계산
- 새로운 클러스터를 재분류
- 클러스터 중심에 변화가 없을 때까지 위에 작업 반복
4. K-means 알고리즘의 단점
- 군집 개수인 k를 미리 지정해야 한다.
- noise and outliers에 민감하다.
- 범주형 데이터가 아닌 숫자 데이터(평균이 정의된 경우)에만 적용 가능
댓글남기기