
7편. 통계의 진화 — 데이터가 말해준 우리 팀의 민낯
바이브코딩 일대기 수학과·컴공과 출신 기획자가 Lovable로 풀스택 앱을 처음 만든 현실 연재. 총 10편.
드디어 꺼내볼 수 있게 됐다
3편에서 DB에 데이터를 넣었다. 4편에서 자체전을 분리했다. 6편에서 버그를 잡았다.
이제 진짜 원했던 걸 할 차례다. 데이터를 꺼내보는 것.
2년치 87경기 데이터가 쌓였을 때 처음 궁금했던 질문들이 있었다.
- 우리 팀은 어느 연령대를 상대로 강하고, 어디에 약한가?
- 구장마다 전적이 다른가?
- 우리는 전반형 팀인가, 후반형 팀인가?
- 진짜 에이스는 누구인가 — 골 수가 아니라 데이터로.
이번 편에서 이 질문들에 답한다.
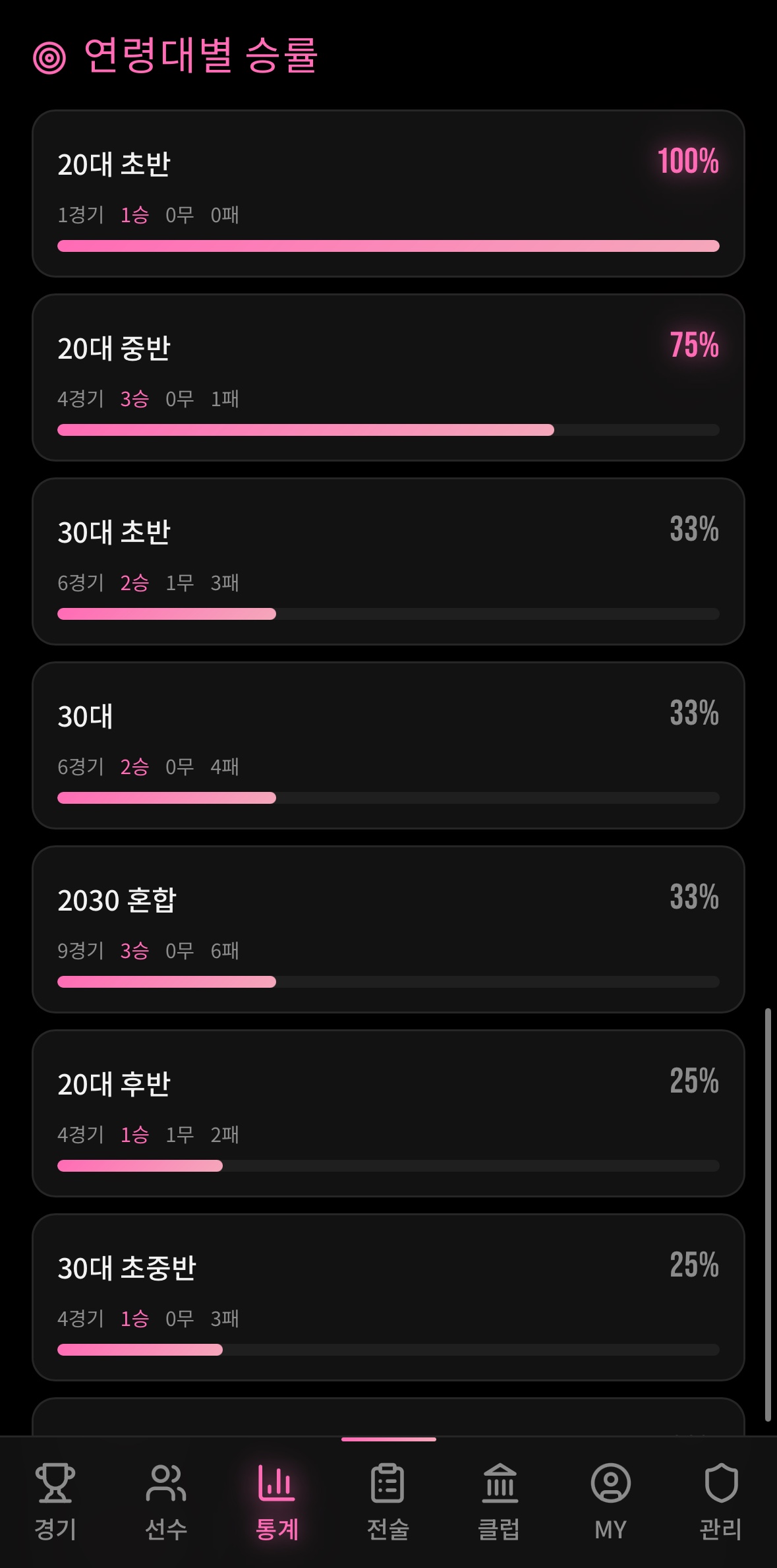
분석 1. 연령대별 승률 — “30대 중반이 제일 무섭다”
가장 먼저 만든 분석이다. 3편에서 age_category를 정규화해둔 이유가 바로 이것이었다.
Gemini한테 요청한 프롬프트:
age_category별 승률을 분석하는 쿼리 짜줘.
자체전 제외, 경기수가 너무 적은 연령대는
신뢰도가 낮으니 최소 3경기 이상인 것만 보여줘.
Gemini가 작성한 쿼리:
SELECT
t.age_category AS "연령대",
COUNT(m.id) AS "경기수",
SUM(CASE WHEN m.result = '승' THEN 1 ELSE 0 END) AS "승",
SUM(CASE WHEN m.result = '무' THEN 1 ELSE 0 END) AS "무",
SUM(CASE WHEN m.result = '패' THEN 1 ELSE 0 END) AS "패",
ROUND(
SUM(CASE WHEN m.result = '승' THEN 1 ELSE 0 END)
* 100.0 / COUNT(m.id), 1
) AS "승률(%)"
FROM matches m
JOIN teams t ON m.opponent_team_id = t.id
-- is_internal = TRUE이면 opponent_team_id = NULL → INNER JOIN에서 자동 제외
GROUP BY t.age_category
HAVING COUNT(m.id) >= 3 -- 최소 3경기 이상만
ORDER BY "승률(%)" DESC;
실제 결과를 차트로 보면:
결과가 흥미로웠다.
20대 초중반 — 승률 72%
체력에선 밀려도 경험이 앞섰다.
30대 중반 — 승률 31%
"걔네 패스가 너무 안정적이야"가 맞았다.
팀원들이 막연하게 느끼던 게 숫자로 나왔다. “우리 30대 중반 팀한테 왜 이렇게 약하지?”가 데이터로 입증된 순간이었다.
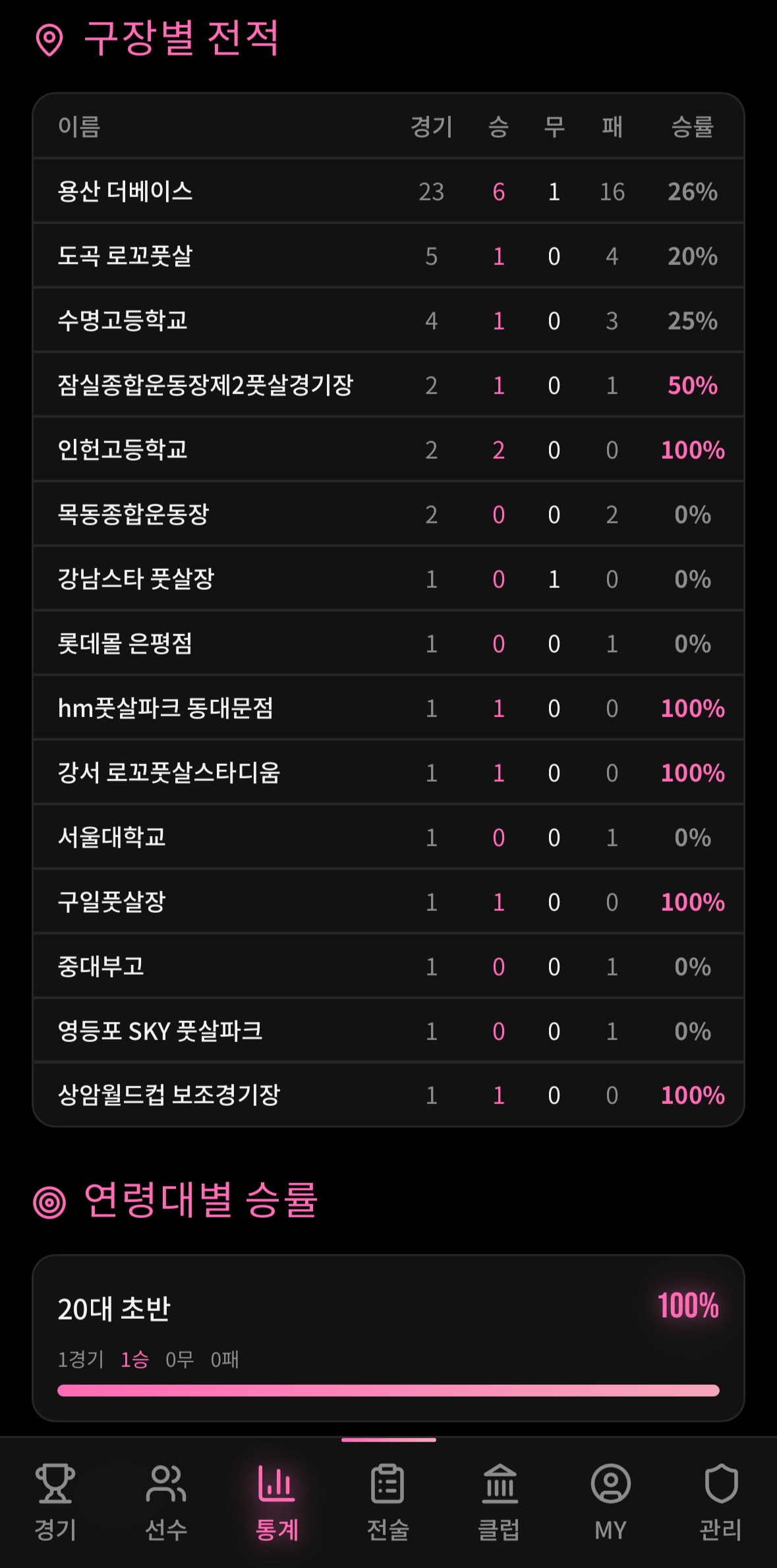
분석 2. 구장별 전적 — “용산 더베이스의 저주”
SELECT
m.venue AS "구장",
COUNT(m.id) AS "경기수",
SUM(CASE WHEN m.result = '승' THEN 1 ELSE 0 END) AS "승",
SUM(CASE WHEN m.result = '패' THEN 1 ELSE 0 END) AS "패",
ROUND(
SUM(CASE WHEN m.result = '승' THEN 1 ELSE 0 END)
* 100.0 / COUNT(m.id), 1
) AS "승률(%)"
FROM matches m
WHERE m.is_internal = FALSE
GROUP BY m.venue
ORDER BY COUNT(m.id) DESC;
| 구장 | 경기수 | 승 | 패 | 승률 |
|---|---|---|---|---|
| 용산 더베이스 | 41 | 14 | 22 | 34% |
| 수명고등학교 | 12 | 6 | 5 | 50% |
| 도곡 로꼬풋살 | 9 | 3 | 6 | 33% |
| 강남스타 풋살장 | 8 | 4 | 3 | 57% |
| 인헌고등학교 | 5 | 3 | 1 | 75% |
용산 더베이스에서 41경기 중 22패. 승률 34%.
“거기 잔디 상태가 별로라서…” 라고들 했지만, 사실 그냥 용산 더베이스에서 강팀들을 많이 만난 것이었다. 구장의 문제가 아니라 상대팀 선택의 문제였다.
분석 3. 쿼터별 득실 추이 — “우리는 초반형 팀이다”
이게 가장 흥미로운 분석이었다.
Gemini한테 요청한 프롬프트:
쿼터별 총 득점/실점을 집계하는 쿼리 짜줘.
자체전 제외.
x축은 쿼터(1~8), y축은 골 수.
우리 팀 득점과 상대팀 득점을 구분해서.
SELECT
ge.quarter AS "쿼터",
SUM(CASE WHEN ge.team_id = '버니즈_team_id'
AND ge.is_own_goal = FALSE
THEN 1 ELSE 0 END) AS "우리팀 득점",
SUM(CASE WHEN ge.team_id != '버니즈_team_id'
OR ge.is_own_goal = TRUE
THEN 1 ELSE 0 END) AS "실점"
FROM goal_events ge
JOIN matches m ON ge.match_id = m.id
WHERE m.is_internal = FALSE
AND ge.quarter BETWEEN 1 AND 8
GROUP BY ge.quarter
ORDER BY ge.quarter;
패턴이 명확하다.
- 1~2쿼터: 우리 팀 득점이 압도적으로 많다
- 5쿼터 이후: 실점이 득점을 역전하기 시작한다
- 7~8쿼터: 완전히 뒤집힌다
우리는 초반형 팀이다. 체력이 떨어지는 후반에 급격히 흔들린다. 이게 감으로 알던 게 데이터로 증명된 순간이었다.
분석 4. 코트 마진(+/-) — 골 없이도 기여한다
골/도움만으로는 선수 기여도를 온전히 측정할 수 없다. 수비수가 잘 막아서 팀이 이겼어도 스탯에 안 잡힌다.
그래서 도입한 게 코트 마진(+/-) 이다.
선수가 필드에 있는 동안 (우리팀 득점 - 상대팀 득점)의 합산
NBA에서 쓰는 지표다. 선수가 뛰는 동안 팀이 얼마나 잘했는지를 측정한다.
계산 쿼리:
SELECT
p.name AS "선수",
SUM(
mq.home_score - mq.away_score
) AS "코트 마진(+/-)"
FROM match_quarters mq
JOIN match_rosters mr
ON mq.id = mr.match_quarter_id
AND mr.position != 'Bench' -- 벤치는 제외
JOIN players p ON mr.player_id = p.id
JOIN matches m ON mq.match_id = m.id
WHERE m.is_internal = FALSE
GROUP BY p.name
ORDER BY "코트 마진(+/-)" DESC;
▶ 코트 마진이 왜 중요한지 — 수학적으로 설명
A선수가 대량 리드 상황에서 골을 많이 넣으면 득점왕이 된다.
근데 그 경기에서 팀이 이긴 건 A선수 덕분이 아닐 수 있다. 코트 마진은 이를 보정한다. 선수가 필드에 있는 동안 팀이 실제로 잘했는지 못했는지를 측정하기 때문이다. 코트 마진 +10이면 → 그 선수가 뛴 쿼터 동안 팀이 10골 더 넣었다는 뜻.
코트 마진 -8이면 → 그 선수가 뛸 때마다 팀이 8골 더 먹혔다는 뜻.
분석 5. PPQ — 진짜 에이스를 가려내는 지표
PPQ = Points Per Quarter (출전 쿼터당 공격포인트)
PPQ = (골 + 어시스트) / 출전 쿼터 수
왜 이게 필요하냐. 단순 득점 합산에는 이런 왜곡이 생긴다.
- 매 경기 나오는 주전 선수는 자연히 골이 많다
- 가끔 나오지만 나올 때마다 터지는 선수가 과소평가된다
PPQ는 “출전 기회 대비 얼마나 효율적으로 기여했는가” 를 측정한다.
Gemini한테 요청한 프롬프트:
PPQ(출전 쿼터당 공격포인트) 랭킹을 뽑고 싶어.
최소 출전 쿼터 기준이 필요해. 10쿼터 이하는 샘플이 적으니 제외해줘.
SELECT
p.name AS "선수",
COUNT(DISTINCT mr.match_quarter_id)
FILTER (WHERE mr.position != 'Bench') AS "출전 쿼터",
COUNT(ge.id)
FILTER (WHERE ge.goal_player_id = p.id
OR ge.assist_player_id = p.id) AS "공격포인트",
ROUND(
COUNT(ge.id)
FILTER (WHERE ge.goal_player_id = p.id
OR ge.assist_player_id = p.id)
* 1.0
/ NULLIF(
COUNT(DISTINCT mr.match_quarter_id)
FILTER (WHERE mr.position != 'Bench'), 0
), 3
) AS "PPQ"
FROM players p
LEFT JOIN match_rosters mr ON p.id = mr.player_id
LEFT JOIN goal_events ge ON p.id IN (ge.goal_player_id, ge.assist_player_id)
AND ge.match_id = mr.match_id
JOIN matches m ON mr.match_id = m.id
WHERE m.is_internal = FALSE
GROUP BY p.name
HAVING COUNT(DISTINCT mr.match_quarter_id)
FILTER (WHERE mr.position != 'Bench') >= 10
ORDER BY "PPQ" DESC;
| 순위 | 선수 | 출전 쿼터 | 공격포인트 | PPQ |
|---|---|---|---|---|
| 1 | 이민혁 | 87 | 62 | 0.713 |
| 2 | 고명석 | 124 | 81 | 0.653 |
| 3 | 신형찬 | 118 | 73 | 0.619 |
| 4 | 이래현 | 131 | 74 | 0.565 |
| 5 | 윤태규 | 143 | 71 | 0.497 |
단순 누적 득점으로는 고명석이 1위였다. 근데 PPQ로 보면 이민혁이 1위다. 출전 쿼터가 적어서 주목받지 못했지만, 나올 때마다 기여한 선수가 따로 있었던 것이다.
Lovable에 요청한 통계 프롬프트
이 분석들을 실제 앱 화면으로 만들 때 사용한 Lovable 프롬프트다.
Gemini가 정리해준 최종 프롬프트:
통계(STATISTICS) 페이지에 아래 섹션들을 추가해줘.
Recharts 라이브러리를 활용하고, 데이터는 Supabase에서 직접 가져와.
[섹션 1. 연령대별 승률]
- 수평 막대그래프
- x축: 승률(%), y축: age_category
- 승률 70% 이상은 초록, 50% 미만은 빨간색으로 색상 분기
[섹션 2. 구장별 전적]
- 테이블 형태, 경기수 기준 내림차순 정렬
- 컬럼: 구장명 / 경기수 / 승 / 패 / 승률
[섹션 3. 쿼터별 득실 추이]
- 라인 차트, x축: 1~8쿼터, y축: 골 수
- 우리팀 득점(초록), 실점(빨강) 두 라인
[섹션 4. PPQ 랭킹]
- 최소 10쿼터 출전자만
- 카드 형태로 상위 5명 표시
- 선수 이름 / 출전 쿼터 / PPQ 수치
모든 섹션 상단에 종합 / 연도별 / 자체전 필터 Select 추가.
필터 변경 시 모든 차트가 즉시 리렌더링 되어야 함.
Supabase goal_events 테이블 분석 대시보드 화면
데이터가 주는 불편한 진실
통계를 꺼내보니 불편한 것들도 나왔다.
실제로 코트 마진 최하위 선수가 있었는데, 알고 보니 그 선수가 항상 상대팀이 강할 때 투입됐기 때문이었다. 데이터만 보면 “팀에 마이너스인 선수”처럼 보이지만, 맥락을 보면 전혀 다른 이야기다.
도메인 지식 없이 데이터만 보면 틀린 결론에 도달한다.
이건 AI한테도 마찬가지다. Gemini한테 “코트 마진 최하위 선수가 누구야?”라고만 물으면 이름만 나온다. “왜 그런지”는 팀을 아는 사람이 해석해야 한다.
이 편에서 배운 것
3편에서 age_category를 정규화할 때는 몰랐다. 이게 나중에 이렇게 쓰일 줄.
데이터 설계가 분석을 결정한다는 말이 진짜라는 걸, 직접 경험하고 나서야 실감했다.
8편에서는 팀원들이 실제로 앱을 쓰기 시작했을 때 나온 반응과, 그 이후 추가된 기능들을 다룬다.
다음 편: 8편. 팀원들의 반응 — 앱이 실제로 쓰이는 날
바이브코딩 일대기 전체 목차는 여기에서 확인할 수 있습니다.
댓글남기기